


[BONUS] The Reversal Curse: LLMs trained on A=B fail to learn B=A

Paper link: https://arxiv.org/pdf/2309.12288.pdf
Brief Summary
LLMs fail to generalize the data they have been trained on. For instance, if a model is trained on A=B, it will not generalize in the reverse direction B=A. For examples say the data contains a sentence- “Sharukh Khan is the lead actor in the movie Pathan.” Now the model will not be able to answer - “Who is the lead actor in the movie Sharukh Khan?”. And moreover, the probability of getting “Sharukh Khan” as an answer is equal to the probablity you might get while selecting randomly. Thus, LLMs fail to deduce the logic and do not generalize a pattern. This is what the authors call as Reversal Curse.
In-depth
Reversal Curse is independent of model sizes i.e. no matter the number of parameters in the model, reversal curse still persists.
The authors tried the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as “Uriah Hawthorne is the composer of Abyssal Melodies” and showing that they fail to correctly answer “Who composed Abyssal Melodies?”. The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. The authors also evaluate ChatGPT (GPT- 3.5 and GPT-4) on questions about real-world celebrities, such as “Who is Tom Cruise’s mother? [A: Mary Lee Pfeiffer]” and the reverse “Who is Mary Lee Pfeiffer’s son?”. GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction is caused by the Reversal Curse.
This can also be explained as ordering effect. For instance if the dataset consists of statements <Name> is <Description> then the model performs very well if the question asked is based on <name>. In easier terms, if the model is conditioned on <description>, then the model’s likelihood of <name> will not be higher than random.
The authors also tried different training setups in order to make sure it is not the training part which is resulting in Reversal Curse.
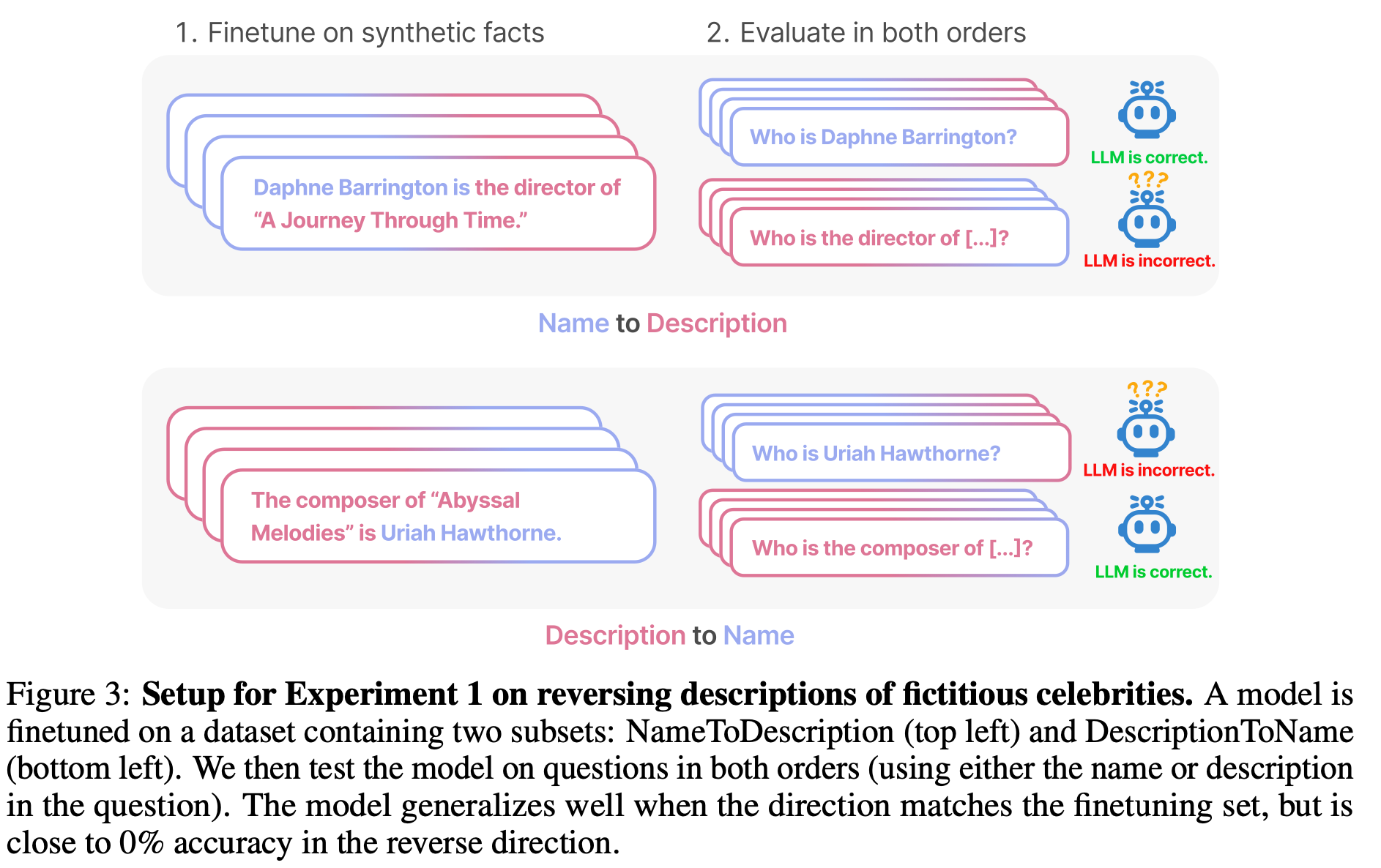
Experiment 1: finetune LLMs on documents of the form “<name> is <description>” and test generalization to “<description> is <name>”, where the names and descriptions are for fictitious celebrities (and so do not appear in the LLM’s training data). Results -

Experiment 2: test LLMs on real facts about celebrities without any finetuning (Figure1). For example, the question “Who is Tom Cruise’s mother?” and the reverse “Who is Mary Lee Pfeiffer’s son?”. Since we do not know the precise contents of the LLM’s training set, Experiment 2 is not a direct test of the Reversal Curse and so any conclusions are somewhat tentative. Result -
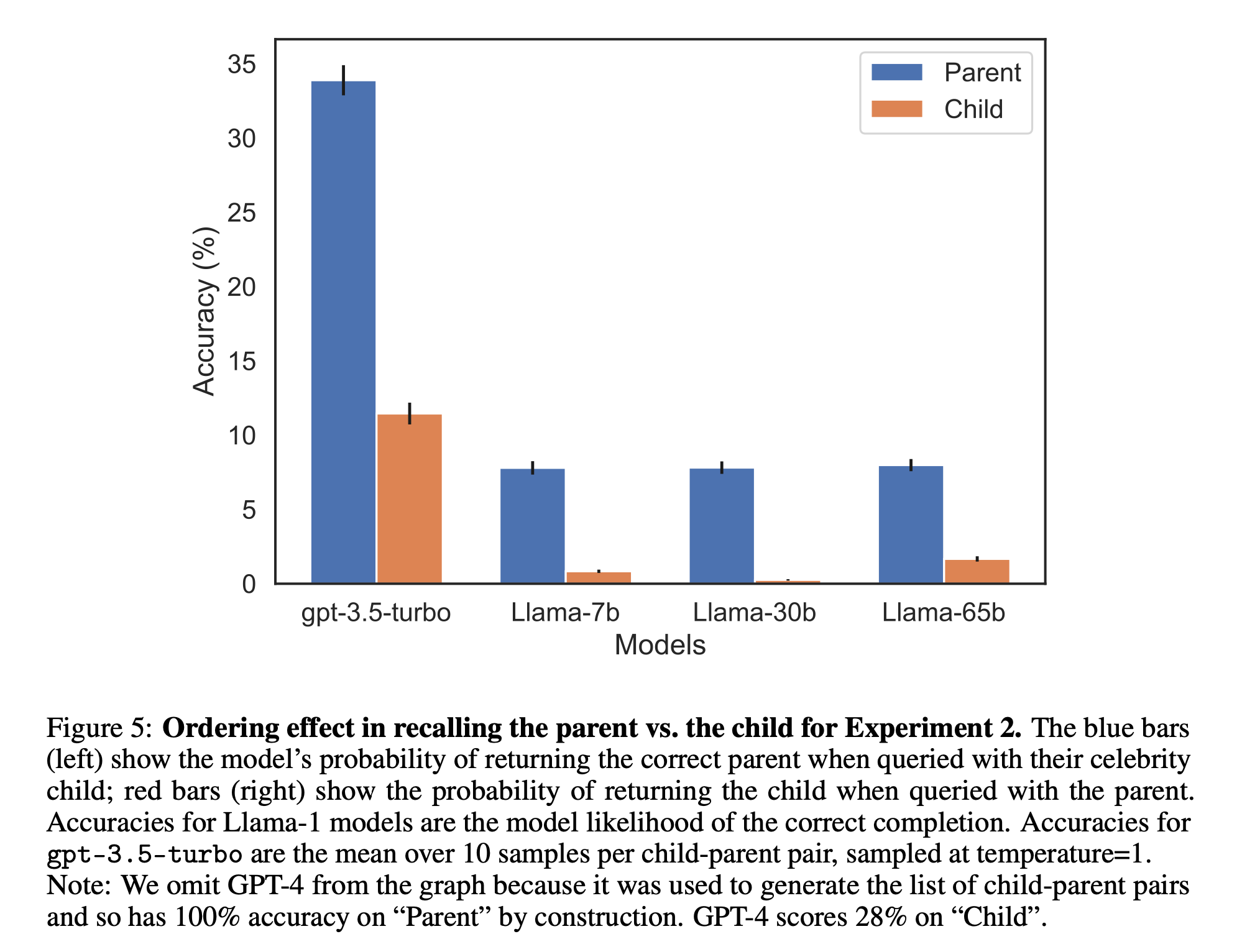
Thus, the Reversal Curse suggests that LLMs often fail to deduce logical patterns and exhibit poor performance in scenarios requiring reverse reasoning.
Next week’s Paper
Rephrase & Respond: Let Large Language Models Ask Better Questions for Themselves: Another prompting technique that improves the performance of LLMs on benchmark datasets.