


[BONUS] Rephrase & Respond: Let Large Language Models Ask Better Questions for Themselves

Paper link: https://arxiv.org/pdf/2311.04205.pdf
Brief Summary
So far we have seen (using Cot, Plan&Solve) that the quality of a prompt, such as a question, significantly impacts the quality of the response provided by LLMs. Therefore, a systematic method for crafting questions that LLMs can better comprehend is still underdeveloped. In this paper, the researchers present a method named ‘Rephrase and Respond’ (RaR), which allows LLMs to rephrase and expand questions posed by humans and provide responses in a single prompt. The experiments demonstrate that the proposed methods significantly improve the performance of different models across a wide range to tasks.
In-depth
Misunderstandings in interpersonal communications often arise when individuals, shaped by distinct subjective experiences, interpret the same message differently. A single message, framed in different ways, can lead individuals to different conclusions. It is widely acknowledged that the quality of the prompt generated by human critically influences the response quality of the LLMs, emphasizing the importance of effective queries that prioritize specificity, detail, and precision. However, because of an individual’s unique frame of thought, it can be challenging for humans to assess the clarity of their questions and to align their frames with those of LLMs.

In this paper, the researchers highlight an often-overlooked aspect of studies in LLMs: the disparity between human and LLM thought frames. The research illustrates that this disparity significantly impacts the performance of LLMs. To tackle this problem, they propose to let the LLM rephrase the question and incorporate additional details for better answering. They observe that, as opposed to questions asked casually by human, the rephrased questions tend to enhance semantic clarity and aid in resolving inherent ambiguity.
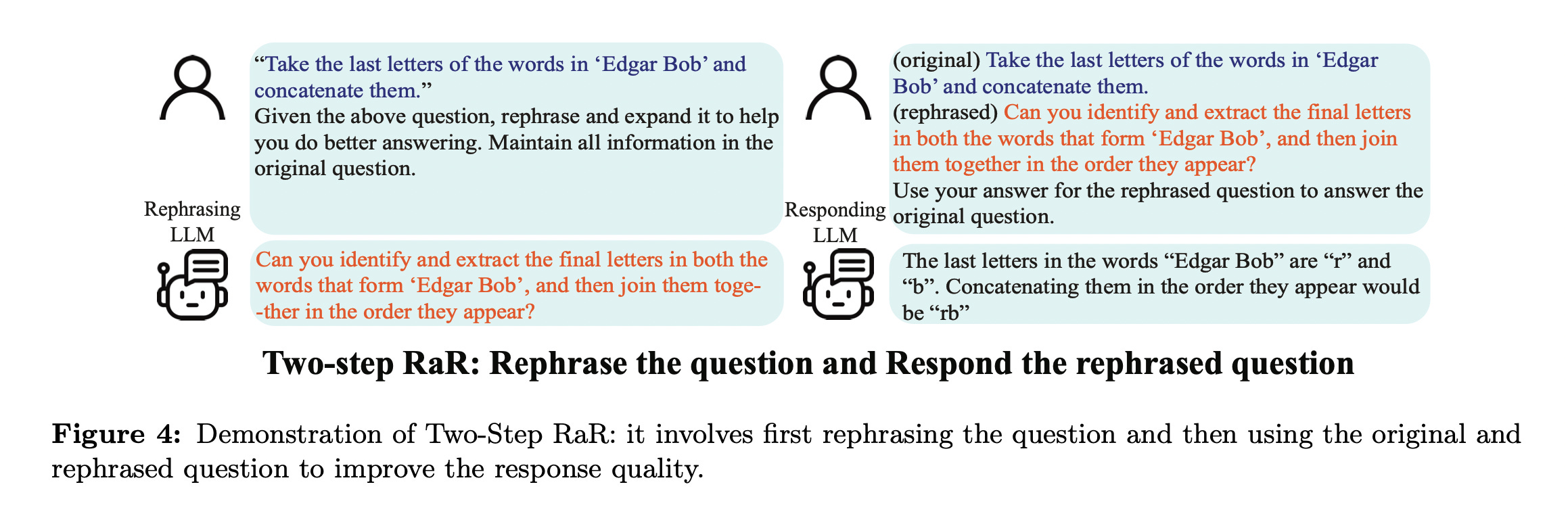
The proposed method is named Rephrase and Respond (RaR), which prompts the LLM to rearticulate the given question and respond in a single prompt. In addition to the simple RaR prompt, they also present a variation called Two-step RaR. Two-step RaR employs a rephrasing LLM to generate reworded questions that can be made available to any responding LLM.

In interpersonal communication, rephrasing is a commonly known technique. People rephrase another person’s question as a process of understanding, to ensure clarity and coherence in responding. Such a communication strategy can be similarly applied to an LLM, letting it generate a rephrased question first and provide an answer subsequently. Following this intuition, they propose RaR to ask the LLMs to Rephrase and Response the question using a single query. This approach can be viewed as a strategy to directly enhance the quality of the LLM’s response. The prompt used is -
"{question}" Rephrase and expand the question, and respond.
GPT-4 achieves much better results using the above RaR prompt across a wide range of tasks, and especially on human-crafted datasets that exhibit ambiguity to LLMs.

To further leverage the quality improvement of the questions rephrased by larger models, like GPT-4, they introduce a variation of RaR called Two-step RaR. Intuitively, even among humans, a more detailed and precise question elicits in more accurate and decisive responses. Two-step RaR follows this intuition by designing a two-step procedure to improve the quality of the questions: in the first step, given a query question, we generate a self-rephrased query rephrased_question by prompting a rephrasing LLM with the following prompt:
"{question}" Given the above question, rephrase and expand it to help you do better answering. Maintain all information in the original question.
Then the original question and the rephrased question are combined to prompt a responding LLM with the following prompt:
(original) {question} (rephrased) {rephrased_question} Use your answer for the rephrased question to answer the original question.
Notably, the rephrasing LLM and the responding LLM can be either the same or different models. Different LLMs exhibit distinct proficiency in question rephrasing. In particular, a question rephrased by GPT-4 can help a weaker LLM like Vicuna to produce more accurate responses.
Results:

Next week’s Paper
LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS: Task performance by LLMs depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans. Inspired by classical program synthesis and the human approach to prompt engineering, the paper propose Automatic Prompt Engineer (APE) for automatic instruction generation and selection.