

#127 Personal Experience: The Truest Teacher in Life's Journey
And understanding how chain-of-thought prompting elicits reasoning in Large Language Models

September 30, 2023

In recent times, when I hear people discussing about their relationships, about politics, or life in general, I often come across viewpoints that seem simplistic or don't make much sense to me. At first, it would bother me, and I'd want to jump in and correct them. However, these days, I hold back. I've come to realize that life has its own way of teaching us. Some lessons are genuinely best learned through personal experiences, and it's not always my place to intervene. After all, we all have our paths of understanding, and sometimes the journey to knowledge is just as important as the destination.
All through our life, we are showered with an endless stream of information, advice, and lessons. The society we live in provides us with guidelines on how to live, what to think, and who to be. However, in the past few years, I have realized that there are countless things that we must discover and understand on our own. The journey of self-realization is an intricate and personal one, but it is essential for genuine personal growth and maturity.
From early on, we are taught the difference between right and wrong, the significance of cultural values, and the importance of societal norms. These lessons are valuable and lay the foundation for our basic understanding of the world. However, they come with their limitations. Not every lesson can be taught; some experiences are so intimate and personal that they can only be truly understood when lived first hand.
Personal experience is an unparalleled teacher. When we go through situations firsthand, we don't just understand them at a superficial or intellectual level; we internalize them. The lessons gleaned from personal experiences become a part of who we are, shaping our beliefs, values, and actions. Furthermore, personal experiences help us develop a unique perspective on life. Two people might go through the same event, but their takeaways might be starkly different based on their past experiences, beliefs, and values. This uniqueness is what contributes to the rich tapestry of human diversity and thought.
The path of self-realization is a deeply personal one, marked by moments of joy, pain, confusion, and enlightenment. It is our personal experiences and reflections that mold our understanding of the world and make us who we are.
Cheers!
Science Unveiled
Last week we discussed about how LLMs fail to generalize concepts and belong to the category of students who memorize stuff. This week we are going to see a method that improving the abilities of these students i.e. make the rote learners more logical.
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Paper link: https://arxiv.org/pdf/2305.15507.pdf
Brief Summary
Chain of thought as a way to improve the scope of what LLMs can do. What is chain of thought? Adding intermediate steps in the form of natural language to improve the model performance. Does not answer much about reasoning. The paper basically says that the capabilities of LLMs expand in various domains such as arithmetic, commonsense, symbolic reasoning as we increase the size of the model and use chain of thought.

Detailed Summary
Natural Language Processing has been revolutionized by the use of LLMs. If you are using any AI product these days, such as ChatGPT, chances are that LLM is the technology behind it. It has been observed that as we scale up the model, i.e. increase the number of model parameters, increase the amount of training data, the model helps in reasoning but is still not enough for arithmetic tasks. Arithmetic reasoning is a task which is easy for humans but models suffer a lot in them. This paper makes use of natural language to improve performance on arithmetic tasks. The paper takes advantage of few-shot learning, which means that we do not need to fine tune model to a specific task (arithmetic reasoning is this case), but just providing a few sample input-output exemplar demonstrating the task will make the model learn. Few shot learning is a very helpful methodology which saves the cost of creating high set of rational datasets to be used for fine tuning the model. The method proposed by the authors consists of a prompt<input, chain of thought, output>
Chain of thought is an intermediate step that explain the process involved for taking input to the output. It has been shown in the paper that sufficiently large language models can generate chains of thought if demonstrations of chain-of-thought reasoning are provided in the exemplars for few-shot prompting. Chain of thought allows the model to decompose the problem into multi step so that computation can be allotted to problems that require more reasoning steps. This is also a very interesting method as it explains the model and is applicable to any task that humans can solve using language
The benchmark mathematical problem sets considered for the paper: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
The paper mentions two types of prompting -
Standard prompting: Consider standard few-shot prompting in which language model is given in-context exemplars of input–output pairs before outputting a prediction for a test-time example. There is no chain of thought input here.
Chain of thought prompting: Augment each exemplar with chain of thought in few shot learning.

The evaluation is done on 5 large models namely - GPT-3, LaMDA, UL2 20B, Codex
RESULTS -
Not useful for smaller models as the performance is not impacted, qualitatively found that models of smaller scale produced fluent but illogical chains of thought, leading to lower performance than standard prompting
Chain-of-thought prompting has larger performance gains for more-complicated problems.
Scaling improves the chain of thought i.e. larger the model size, the better quality chain of thoughts produced.

The diagram above clearly shows that for larger model sizes (model scale), chain-of-thought prompting surpasses the benchmark. While standard prompting does improve performance as the size increases, it falls short of both the benchmark and the chain-of-thought prompting method. It can also be observed that when the model scale is less, the performance of chain-of-thought prompting is similar to that of standard prompting because of the quality of chain of thoughts generated by small models.
The paper also mentions different ablation studies that highlight how chain-of-thought is the only variable in this work responsible for improving the model performance as the model scales up. Feel free to refer the paper to understand the ablation study methods used.
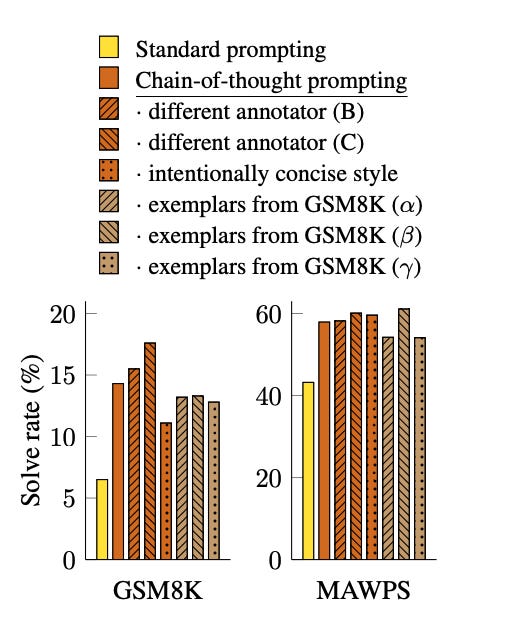
The above graph is for LaMDA trained on 137Billion parameters. It can be clearly seen that all the chain-of-thought methods perform better than the standard prompting although they differ by some margin owing to different thought styles written by different persons. This implies that successful use of chain of thought does not depend on a particular linguistic style. In addition to robustness to annotators, independently-written chains of thought, different exemplars, and various language models, the paper also finds that chain-of-thought prompting for arithmetic reasoning is robust to different exemplar orders and varying numbers of exemplars.
Apart from mathematic reasoning tasks, the paper also shows the use of chain-of-thought prompting on Commonsense reasoning and Symbolic reasoning and shows that chain-of-thought method does take the model evaluation past the previous benchmark results.
Feel free to dig into the paper to get a better understanding. Let me know in the comment section if you like it!
Take care, have fun, see you soon :)
So thoroughly enriching